Author Archives: whitehatty
#InfluxDB : readable timestamps in the CLI
Time-series database InfluxDB provides a nice CLI, similar to what is available for many other databases.
One key feature of the interaction with time series databases is to work a lot with time, so it comes a little bit surprising that InfluxDB displays time as nanoseconds timestamp, like the following:
892482496000000000To have human-readable timestamps invoke the CLI as the following:
$influx -precision rfc3339or type the following command at the CLI propmpt:
> precision rfc3339The timestamp will then look like:
1998-04-13T15:48:16Zbetter right? 🙂
#InfluxDB : drop all measurements
InfluxDB is a popular time series databases. Its popularity comes from the fact that it is relatively easy to set up, it has relatively high performances, and InfluxQL, a simple SQL-like query language (which is being superseded by flux for a host of reasons).
That said, DB management functions are really important and while playing around with your algorithms (e.g., while doing time series forecasting) you might end up generating quite a few measurements (Influx jargon for table/collection) which we might want to delete at one…If it wasn’t for the fact we can’t!
At least we can drop the whole database (let’s say we have a db named forecasting):
DROP DATABASE forecastingbut if that solution does not work for you (e.g., because you do not have such right, or because you set up some specific retention policies) we are left with a couple of solutions.
Solution 1 does not work on all versions, it is slow, but can be invoked from within Influx shell:
DROP SERIES FROM /.*/Solution 2 is a simple bash script:
for mes in `influx -username root -password root -database forecasting -execute 'show measurements' --format csv | awk -F "\"*,\"*" '{print $2}'`;doinflux -username root -password root -database forecasting -execute 'drop measurement "${mes}"';done#Linux : extract substring in #Bash
One of the most important tasks in dealing with data is string manipulation. We already saw how to use awk and grep to efficiently sift through text files using command line tools instead of developing ad-hoc code. To step it up a notch, we can also do some heavier preprocessing of the data, such as selecting only the subset of information that matches a particular pattern, to ensure data coming out of our pipeline is of good quality.
In this case, we use a Bash feature called parameter expansion. Let’s assume we have the text data in a variable TEXT_LINE and an expression pattern to match (in file-name matching format), this is a summary of the possible expansion:
- Delete shortest match of pattern from the beginning
${TEXT_LINE#pattern} - Delete longest match of pattern from the beginning
${TEXT_LINE##pattern} - Delete shortest match of pattern from the end
${TEXT_LINE%pattern} - Delete longest match of pattern from the end
${TEXT_LINE%%pattern} - Get substrings based on position using numbers
${TEXT_LINE:START:END} - Replace particular strings or patterns
${TEXT_LINE/pattern/replace}
So for example, to extract only the file name without the extension:
${TEXT_LINE%.*}or to extract user name from an email:
${TEXT_LINE%%@*.*}or extract the file name from an absolute path:
${TEXT_LINE##*/}NOTE: You can’t combine two operations, instead you have to assign to an intermediate variable.
#Linux : How to Slice an Array in #Bash
A lot of things can be done using just the command line.
In fact, Bash shell scripting language is a touring-complete language, so anything can be done!
One important feature is the ability to slice an array (i.e. select a contiguous subset of elements of a collection).
So let’s say for example we stored the list of installed packages into a variable PACKAGE_LIST as a bash array:
#PACKAGE_LIST=(`dpkg -l | awk '{print $2}'`)and for some reason we want to select elements from 4 to 10:
#PACKAGE_LIST=${PACKAGE_LIST[@]:3:10}Let me explain. Here, we are using Bash parameter expansion:
-
The
[@]following the array name returns the whole content of the array. - The
:X:Ypart is doing the slicing by taking a slice of lengthYstarting at positionX. Note that ifXis negative, that is we start atXelements from the end, we must put a space between the colon and the number.
#Linux : list all packages installed
Sometimes we want to quickly check if we have a required package installed, for example a developer library we need to compile our code.
If you are running a Debian based Linux system such as Ubuntu, you have a couple of alternatives. Using apt, let’s say we are looking for python3-dev since it is required to debug python code through gdb:
#sudo apt list --installed | grep python3-devHowever, you will notice apt is pretty slow and we will be greeted by the warning WARNING: apt does not have a stable CLI interface. Use with caution in scripts.. Moreover, the output is not so nice if we want to parse it in a scripted way. A faster alternative is provided by dpkg:
#sudo dpkg -l | grep python3-devIn RedHat and RedHat-like Linuxes such as Fedora and CentOS we can use either rpm:
#sudo rpm -qa | grep python3-devor yum:
#sudo yum list installed | grep python3-dev#Docker: copy files and folders between a container and the local filesystem
Container technology lead to a dramatic shift in computing paradigms and it is exceptionally useful in contexts where platform independence and reproducibility are important factors. This is the case for example in Machine Learning and AI applications. Containers are at the base of ML platforms such as Michelangelo (Uber), Bighead (Airbnb), Databricks, Domino, etc.
So now you are happily running your stuff in containers and tinkering around, when you need to pull out a file from one of them for e.g., check the output of an algorithm is correct, or you need to paste a directory containing a new shiny hand-made dataset to quickly test. If this was a linux machine you could just use scp command and call it a day, so you will be glad docker now offers its own cp-like command.
So for example let’s say we want to copy the file output.txt that is saved in the home of a running container to our desktop for some analysis. We grub the container id using docker ps command (in these examples b0e70cca9782) and we issue the following command:
#docker cp b0e70cca9782:/home/output.txt ~/DesktopLikewise, if we have a directory containing test images and we want to copy it in the home directory of the container to test our algorithm further we can do:
#docker cp ~/Desktop/images b0e70cca9782:/home/#Linux : use grep to extract lines around a pattern match
In the text processing toolkit of every sys admin or data scientist out there there is a well known command line utility of which utility is second to none (ok, maybe sed is a strong contender): grep.
So “grepping” has become a known term among developers and it has the same meaning as “googling”, that is find something that matches my query in this file. Grep will return the list of rows matching the specified pattern.
However sometimes it is useful to have some context around the pattern match, especially if we are talking about system logs; in this case grep has a couple of little known flags that are super useful: -A, for after the pattern match, and -B for before.
For example to display 10 lines before and 15 lines after any system log line that contains the word error:
#journalctl --no-pager | grep "error" -A 15 -B 10#Linux : data processing with awk
As a data scientist, a lot of time is spent into parsing and processing data to transform it into a nicer format that can be easily fed to whichever algorithm is being used. This process is often known as ETL.
There are a number of tools for the job ranging from command line utils, language libraries, and even whole products that go all the way to Petabyte scale (e.g., Spark).
Here I will give one tip for a unix/linux command line util that is often forgotten but that has a lot of functionality, it is fast and memory efficient (can process tens of thousands of rows per second, scale to multiple cores by using unix pipelining), and it is available pretty much anywhere (while your preferred tool or library might not). The awesome AWK!
Now, AWK can do pretty much anything, but here are just 2 bits that are exceptionally useful as a starting point of our data processing.
- Select by column (e.g, select a field of a csv file) is achieved by using the special variable $i where i is the column position we want to select, e.g., to print the second column
#awk -F "\"*,\"*" '{print $2}' filename.csv - Select by row (e.g., iterate through a csv file) is achieved using the built-in variable FNR, e.g., to print the second row
#awk 'FNR == 2 {print}' filename.csv
For a primer you can look HERE. Happy AWKing! 😎
#Python : debugging your python processes with GDB
PyCharm is an awesome IDE, and its debugger is a massively useful tool to help in code development.
However, there are instances where the bug express itself only at runtime in conditions that are hard to reproduce on the developer machine or where traces are not available. Example of these types of bugs that are difficult to debug from within Python are:
- segfaults (not uncaught Python exceptions)
- hung processes (in cases where you can’t get a Python traceback or debug with pdb)
- out of control daemon processes
- python processes running in a Docker container in a production environment
In these cases, you can try gdb.
Let’s take the case of your python process running in a Docker container. You can get a shell into the container and install a couple of packages (e.g., for Ubuntu Linux):
#apt-get install gdb python2.7-dbgNow you are ready to debug your process either interactively
#gdb python
...
(gdb) run [program name].py [arguments]
or automatically:
#gdb -ex r --args python [program name].py If the process is already running (which will be the case if in production and the bug did not cause the process to terminate):
#gdb python [pid of process]
Happy debugging! 😎
#Kali Linux: TP-LINK WN821N Compatible Wireless Adapter for Mac OS X and VMware Fusion
The list of compatible adapters is often very short, and confusing because the support depends on the operating system and often it breaks when updating Kali.
In particular, nothing is said about Mac OS X compability.
Here the good news, I tested the TP-LINK WN821N USB adapter and it seems to work properly in Kali Linux 2016.x installed in VMware Fusion (VMware Fusion 8.5.3 on Mac OS X El Capitan 10.11.6). The TP-LINK WN821N is athereos based and it supports 802.11n standard at 300 Mbps and it is quite cheap. You can buy it on Amazon HERE. Stay away from TP-LINK Archer T4UH (AC1200) which is Realtek based and its Linux drivers are badly outdated (but it is a good adapter under Windows, with over 200Mbps throughput).
These are the very basic steps:
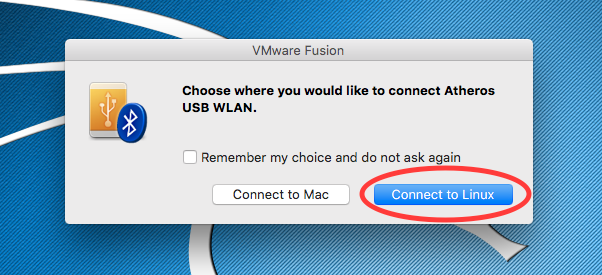
- Once you booted the system and logged in as root, you can connect the USB wireless adapter. VMWare will ask you to select if connect it to Linux or to the Mac. Select to connect it to Linux.

- You should now see the adapter in
airmon-ng

- You can then start
airmong-ng. The command show the interface created for monitoring.

- The final steps are to run
airodump-ngto extract the MAC addresses and useairplay-ngto lunch a deauthentication attack. For the full tutorial see HERE.


#Kali Linux: Install VMware Tools
If you are running a recent version of VMware Player, VMware Workstation, or VMware Fusion along with a recent Linux Kernel (>=4.4), then the recommended way to install VMware tools is to use the package for Open VM Tools (OVT) provided by your distribution. For Kali Linux
#apt-get install open-vm-tools-desktopThat’s it you are all set. If you do not like it, you can always go with the old way.
#Kali Linux: fix sources.list
If you are running Kali Linux 2016.x which is in a rolling release, you might need to update the source list for apt in order to update the system.
If you see something like the following:
#apt-get updateReading package list... Doneit means your sources.list file needs to be fixed.
In this case you can use this one-liner from the root prompt:
#echo "deb http://http.kali.org/kali kali-rolling main contrib non-free" >> /etc/apt/sources.listNow you can update your system:
#apt-get update && apt-get upgrade -y#MacOsX : Terminal Cheat Sheet
If you are a *nix geek like me you can’t but love the command prompt.
One of the best tool to improve the plain old terminal is an utility called tmux. You can install through Homebrew.
Now, there are many commands to remember to play nicely with the terminal, and sometimes a little remind might be useful, that’s why cheat sheets exist.
Here is mine, enjoy.
#cURL : HOWTO [UPDATED]
You can use the cURL library and the curl command to design your own Request and explore the Response. There are many possible uses like e.g., API debug, web hacking, pen testing.
curl is a tool to transfer data from or to a server, using one of the supported protocols (e.g., FTP, GOPHER, HTTP, HTTPS, IMAP, LDAP, POP3, RTMP, SCP, SFTP, SMTP, TELNET). The command is designed to work without user interaction.
curl offers a busload of useful tricks like proxy support, user authentication, FTP upload, HTTP post, SSL connections, cookies, file transfer resume, Metalink, and more. As you will see below, the number of features will make your head spin!
So curl is a truly powerful command, however it does at the cost of complexity. Here I will show some real-world use cases.
URL
The URL syntax is protocol-dependent. If you specify URL without protocol:// prefix, curl will attempt to guess what protocol you might want. It will then default to HTTP but try other protocols based on often-used host name prefixes. For example, for host names starting with “ftp.” curl will assume you want to speak FTP.
You can specify multiple URLs or parts of URLs by writing part sets within braces as in:
curl en.wikipedia.org/wiki/{FTP,SCP,TELNET}or you can get sequences of alphanumeric series by using [ ] as in:
curl forums.macrumors.com/showthread.php?t=[1673700-1673713]curl numericals.com/file[1-100].txtcurl numericals.com/file[001-100].txtcurl letters.com/file[a-z].txtNested sequences are not supported, but you can use several ones next to each other:
curl any.org/archive[1996-1999]/vol[1-4]/part{a,b,c}.htmlYou can specify any amount of URLs on the command line. They will be fetched in a sequential manner in the specified order.
You can specify a step counter for the ranges to get every Nth number or letter:
curl numericals.com/file[1-100:10].txtcurl letters.com/file[a-z:2].txtTrace Dump
In order to analyze in depth what we send and receive we might save everything on a file, this is as easy as:
curl --trace-ascii DebugDump.txt URLSave To Disk
If you want save the Response to disk you can use option -o <file>. If you are using {} or [] to fetch multiple documents, you can use ‘#‘ followed by a number in the specifier. That variable will be replaced with the current string for the URL being fetched. Remember to protect the URL from shell by adding quotes if you receive the error message internal error: invalid pattern type (0). Examples:
curl 'en.wikipedia.org/{FTP,TFTP,SFTP}' -o "#1.html"curl arxiv.org/pdf/13[01-11].36[00-75].pdf -o "arXiv13#1.36#2.pdf"Option -O writes output to a local file named like the remote file we get (only the file part of the remote file is used, the path is cut off). The remote file name to use for saving is extracted from the given URL, nothing else. Consequentially, the file will be saved in the current working directory. If you want the file saved in a different directory, make sure you change current working directory before you invoke curl:
curl -O arxiv.org/pdf/1301.3600.pdfOnly the file part of the remote file is used, the path is cut off, thus the file will be saved as 1301.3600.pdf.
Set HTTP Request Method
The curl default HTTP method, GET, can be set to any method you would like using the -X <command> option. The usual suspects POST, PUT, DELETE, and even custom methods, can be specified:
curl -X POST echo.httpkit.comNormally you don’t need this option. All sorts of GET, HEAD, POST and PUT requests are rather invoked by using dedicated command line options.
Forms
Forms are the general way a web site can present a HTML page with fields for
the user to enter data in, and then press some kind of ‘submit’
button to get that data sent to the server. The server then typically uses
the posted data to decide how to act. Like using the entered words to search
in a database, or to add the info in a bug track system, display the entered
address on a map or using the info as a login-prompt verifying that the user
is allowed to see what it is about to see.
Using the -d option we can specify URL encoded field names and values:
curl -d "prefisso=051" -d "numero=806060" -d "Prosegui=Verifica" -d "form_name=verifica_copertura_ehiveco" http://www.ovus.it/verifica_copertura_ehiveco.php
A very common way for HTML based application to pass state information between pages is to add hidden fields to the forms. Hidden fields are already filled in, they aren’t displayed to the user and they get passed along just as all the other fields. To curl there is no difference at all, you just need to add it on the command line.
Set Request Headers
Request headers allow clients to provide servers with meta information about things such as authorization, capabilities, and body content-type. OAuth2 uses an Authorization header to pass access tokens, for example. Custom headers are set in curl using the -H option:
curl -H "Authorization: OAuth 2c4419d1aabeec" http://echo.httpkit.comcurl -H "Accept: application/json" -H "Authorization: OAuth 2c3455d1aeffc" http://echo.httpkit.comNote that if you should add a custom header that has the same name as one of the internal ones curl would use, your externally set header will be used instead of the internal one. You should not replace internally set headers without knowing perfectly well what you’re doing. Remove an internal header by giving a replacement without content on the right side of the colon, as in: -H "Host:".
If you send the custom header with no-value then its header must be terminated with a semicolon, such as -H "X-Custom-Header;" to send "X-Custom-Header:".
curl will make sure that each header you add/replace is sent with the proper end-of-line marker, you should thus not add that as a part of the header content: do not add newlines or carriage returns, they will only mess things up for you.
Referer
A HTTP request may include a referer field (yes it is misspelled), which can be used to tell from which URL the client got to this particular resource. Some programs/scripts check the referer field of requests to verify that this wasn’t arriving from an external site or an unknown page. While this is a stupid way to check something so easily forged, many scripts still do it.
This can also be set with the -H, --header flag of course. When used with -L, --location you can append ";auto" to the --referer URL to make curl automatically set the previous URL when it follows a Location: header. The ";auto" string can be used alone, even if you don’t set an initial --referer.
curl -e google.com http://echo.httpkit.comUser Agent
To specify the User-Agent string to send to the HTTP server you can use --user-agent flag. To encode blanks in the string, surround the string with single quote marks. This can also be set with the -H, --header option of course. Many applications use this information to decide how to display pages. At times, you will see that getting a page with curl will not return the same page that you see when getting the page with your browser. Then you know it is time to set the User Agent field to fool the server into thinking you’re one of those browsers:
curl -A "Mozilla/5.0 (iPhone; U; CPU iPhone OS 4_3_2 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8H7 Safari/6533.18.5" http://echo.httpkit.comCookies
The way the web browsers do “client side state control” is by using cookies. Cookies are just names with associated contents. The cookies are sent to the client by the server. The server tells the client for what path and host name it wants the cookie sent back, and it also sends an expiration date and a few more properties.
When a client communicates with a server with a name and path as previously specified in a received cookie, the client sends back the cookies and their contents to the server, unless of course they are expired.
Many applications and servers use this method to connect a series of requests into a single logical session. To be able to use curl in such occasions, we must be able to record and send back cookies the way the web application expects them. The same way browsers deal with them.
It is supposedly the data previously received from the server in a "Set-Cookie:" line. The data should be in the format "NAME1=VALUE1; NAME2=VALUE2".
If no = symbol is used in the line, it is treated as a filename to use to read previously stored cookie lines from, which should be used in this session if they match. Using this method also activates the “cookie parser” which will make curl record incoming cookies too, which may be handy if you’re using this in combination with the -L, --location option. The file format of the file to read cookies from should be plain HTTP headers or the Netscape/Mozilla cookie file format. NOTE that the file specified with -b, --cookie is only used as input. No cookies will be stored in the file. To store cookies, use the -c, --cookie-jar option or you could even save the HTTP headers to a file using -D, --dump-header:
curl --cookie "name=whitehatty" http://echo.httpkit.comcurl -c cookies.txt http://www.facebook.comsed -i '' s/#HttpOnly_\.facebook\.com/echo\.httpkit\.com/g cookies.txtcurl --cookie cookies.txt http://echo.httpkit.comcurl -b cookies.txt --cookie-jar newcookies.txt http://echo.httpkit.comcurl --dump-header headers_and_cookies http://www.facebook.comWork In Progress…
Ok there are many more options, but I will stop here for now. I will add something in the future, so if you have any request (like using more real urls) just leave a comment.
#MacOsX : SSH SOCKS Proxy (SSH Tunnel Web Traffic)
After PRISM scandal you may feel the need to secure your connection and protect your privacy. Then it is a good idea to tunnel web traffic through a secure encrypted connection. This allows your traffic to traverse a local network without being visible to snoopers, even when visiting unencrypted web sites.
What you need:
- a modern browser like Firefox, Chrome or Safari (they support SOCKS4 protocol)
- ssh client (already installed in Mac Os X)
- a shell account (with ssh access)
If you don’t have a shell account, you can find a free one HERE, or HERE, or HERE, or HERE.
To start the local proxy type:
ssh -D PORT user@hostwhere PORT is a local port between 1024 and 65535 (they do not require super user privileges), user is the username at the remote machine, and host is the identifier of the remote host.
That’s not enough, you need to configure the system to use the proxy. Go to System Preferences > Network > [select active interface] > Advanced... > Proxies and check SOCKS Proxy.
Then modify SOCKS Proxy Server info to use the PORT you chose before.
That’s it! From now on all connections on the active network interface will be tunneled through the proxy. 😎
NOTE1: you may want use proxy browser settings instead of system wide proxy settings, so you can tunnel only part of the traffic (e.g. the most sensitive one). This is easy, but the procedure slightly change between different browsers.
NOTE2: you may need to add the option -p HOST_PORT if the remote host doesn’t use the standard ssh port 22, e.g.:
ssh -D PORT user@host -p 666#MacOsX : Mavericks Improve Virtual Machine Graphic Performance
I have made a short benchmark comparison of Parallels vs Fusion 5.0 HERE. VMWare Fusion has reached version 5.0.3, but it looks like VMWare has become lazy and those updates are not worth mentioning. However Apple released Mavericks recently, with an updated graphic stack which has slightly better graphics performance:
| Component | Lion/Mountain Lion | Mavericks |
| Processor: | 4.4 | 4.4 |
| Memory (RAM): | 5.5 | 5.5 |
| Graphics: | 5.0 | 5.0 |
| Gaming graphics: | 4.2 | 4.3 |
| Primary hard disk: | 7.7 | 7.7 |
Moreover, VMs seem to boot much faster under Mac Os X Mavericks.
N.B. you need to update VMWare Fusion to version 5.0.3 in order to have the best experience in Mavericks (or install VMWare Fusion 6).
#MacOsX : Show Hidden Files and Folders
In *NIX systems file and folders beginning with a dot (e.g., .name) are not visible in the Finder (also known as file browser). Since Mac Os X it’s a certified UNIX that’s also the case. If you use the terminal you can use the command:
ls -aHowever, most people will use regular Finder. To enable view of hidden files in the Finder use this command:
defaults write com.apple.finder AppleShowAllFiles -bool TRUEand then restart the finder with the following command:
killall FinderTo revert the changes use the same command, but replace TRUE with FALSE.
#AmazonStudent : Save Money
If you are a student, you can save some bucks if you join Amazon Student, the beautiful thing is that it is absolutely free!!!
That’s not all, you can earn 5$ every time someone join thank to you!
Why don’t you take the time to offer me a free beer clicking the following link and registering? Thx you 😎
#MacOsX : vimrc
If you are looking to configure Vim you find the default configuration file in:
/usr/share/vim/vimrcCopy and rename it in your home directory:
cp /usr/share/vim/vimrc ~/.vimrcHowever it is bare minimal so it is better if you personalize it a bit. One very simple example is the following:
" Configuration file for vim
set modelines=0 " CVE-2007-2438
" Normally we use vim-extensions. If you want true vi-compatibility
" remove change the following statements
" Use Vim defaults instead of 100% vi compatibility
set nocompatible
" more powerful backspacing
set backspace=2
" Display line numbers on the left
set number
" Allow intelligent auto-indenting for each filetype
" and for "plugins that are filetype specific.
filetype indent plugin on
" Fallback when no filetype-specific indenting is enabled
set autoindent
" Enable syntax highlighting
syntax on
" Display the cursor position
set ruler
" Don't write backup file if vim is being called by "crontab -e"
au BufWrite /private/tmp/crontab.* set nowritebackup
" Don't write backup file if vim is being called by "chpass"
au BufWrite /private/etc/pw.* set nowritebackup
